摘要: 尽管脉冲神经网络(Spiking Neural Networks, SNNs)在多个领域表现出显著的能效优势,但在固定时间步长内脉冲神经元的有限发放模式限制了信息表达,阻碍了SNN性能的进一步提升。此外,目前的SNN实现通常将最后一层的发放率或平均膜电位作为输出,缺乏对其他可能性的探索。在本文中,我们指出,脉冲神经元的有限发放模式来源于初始膜电位(Initial Membrane Potential, IMP)的设定,该值通常为0。通过调整IMP,脉冲神经元能够生成更多的发放模式及模式映射。此外,我们发现,在静态任务中,随着膜电位从零开始演化,SNN在每个时间步的准确率都会提高。这一观察启发我们提出了一种可学习的IMP机制,该机制能够加速膜电位的演化,并在有限时间步内实现更高性能。此外,我们引入了“最后时间步”(Last Time Step, LTS)方法,用于加速静态任务中的收敛,并提出了一种标签平滑时间高效训练(Label Smooth Temporal Efficient Training, TET)损失函数,以缓解原始TET方法中优化目标和正则化项之间的冲突。我们的方法相比基线在ImageNet上将准确率提高了4.05%,并在CIFAR10-DVS和N-Caltech101上分别达到了87.80%和87.86%的最新性能。代码已公开,地址为:https://github.com/StephenTaylor1998/IMP-SNN。
1. Intro
Conversion based的方法,尤其是处理静态输入的方法,已经有了比较好的性能,但是这些方法直接忽视了SNN在时间上的维度,忽略了这种生物可解释性。不管是转换的还是训练的方法的主要优势一般都是能效,并且把最后一层的发放率或者membrane potential作为输出。
本文主要研究的是Initial Membrane Potential,初始膜电位IMP在静态任务上对模型Accuracy的影响。
Contribution:
- 我们发现通过调整 IMP 值,SNNs 能够生成新的发放模式,并证明在静态任务中,SNN 准确率的变化仅由膜电位变化引起。此外,我们创新性地在 SNN 中引入了可学习的 IMP,以加速膜电位的演化。
- 为缓解 TET 在静态任务中的收敛缓慢问题,我们提出了 LTS 方法,可加速静态任务的收敛速度。此外,我们构建了标签平滑的 TET 损失函数,以进一步提升 SNNs 在类脑任务中的性能。
- 在类脑数据集和大规模静态数据集 ImageNet1k 上,我们的方法相较于基线模型取得了显著提升。此外,与原始模型相比,计算开销和推理速度几乎没有差异。
2. Related Works
Neuron Dynamics Modeling:
提出了漏积累与模拟发放(Leaky Integrate and Analog Fire, LIAF)脉冲神经元,用模拟值替代二进制脉冲进行传递,缓解了SNN性能下降的问题。参数化漏积累与发放(Parametric Leaky Integrate-and-Fire, PLIF)脉冲神经元的引入使得设计可学习的动态模型成为可能,从而使每个神经元能够学习最优的膜时间常数,提升神经元的多样性。门控漏积累与发放(Gated Leaky Integrate-and-Fire, GLIF)神经元采用通道级参数化的方法,对脉冲神经元进行全面参数化,包括可学习的衰减机制、膜电位阈值、复位电压、输入导电性和门控因子。多级发放方法则通过集成具有不同阈值的神经元来实现多级发放,增强了表达能力,并实现了更高效的梯度传播。并行脉冲神经元的研究通过移除膜电位复位过程,重新定义了一种非迭代的动态机制,从而解决了普通脉冲神经元在学习长期依赖方面的困难。
Direct Training Methods:
脉冲神经元在前向传播阶段发出的二进制脉冲由阶跃函数生成,而阶跃函数是一种不可微的激活函数。在反向传播阶段,可以用代理梯度(Surrogate Gradient, SG)替代阶跃函数来实现直接训练。目前最常见的直接训练方法是时间反向传播(Backpropagation Through Time, BPTT),该方法将脉冲神经网络(SNNs)视为一种特殊的循环神经网络(RNN)。在这种方法中,梯度沿时间维度向后传播,相较于对应的ANNs,这需要更多的计算资源和内存。
在此基础上,tdBN探索了SNN的归一化方法,并首次实现了在ImageNet数据集上对大规模SNN的直接训练。基于这一工作,提出了一种更高效的归一化方法,称为TEBN,其通过使用不同的权重对每个时间步的突触输入进行重新缩放。时间高效训练(TET)使SNNs相较于标准直接训练(SDT)能够收敛于更平坦的极小值,从而提升了泛化能力。OTTT 和SLTT简化了BPTT中沿时间维度的梯度计算,显著降低了内存和计算成本。
3. Analysis of Membrane Dynamics
3.1. Preliminary of Spiking Neurons and Loss Functions
LIF Formulate:
SNN Direct Training的常见Loss包括SDT(对每个timestep的输入求均值得到最后的输出):
和TET(认为每个timestep都有一个输入,分开算完之后聚合los):
3.2. Membrane Dynamics Related to IMP
当前的 SNN 实现中,膜电位通常在每个任务之前被重置为零。然而,通过一些实验及结果分析,我们发现调整 IMP 可以生成新的发放模式和模式映射。
Observation 1: Novel firing patterns under constant intensity input can be generated by adjusting IMP.
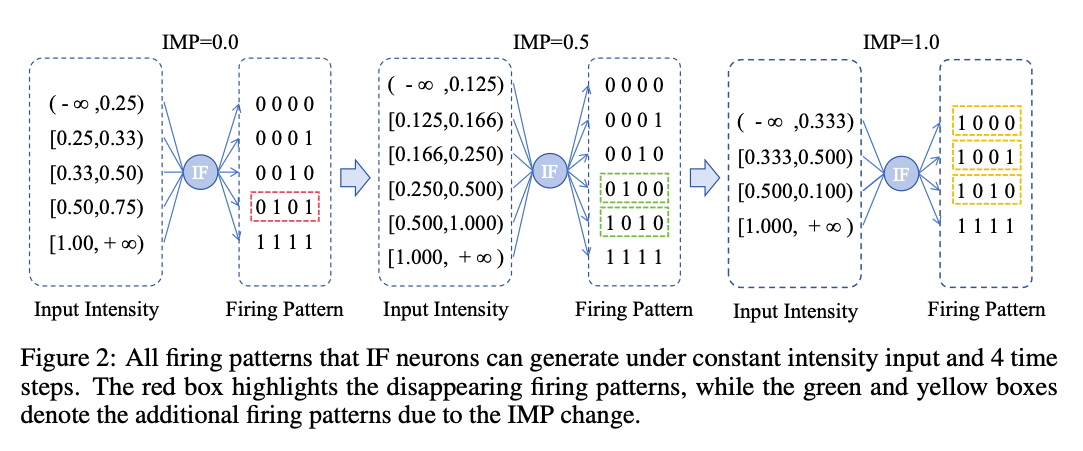
调整IMP发现,不同的初始值可以让模型的输出模式发生变化,相当于有助于增强模型编码输入的能力,提高表达能力。
Observation 2: New mappings of firing patterns can be generated by adjusting IMP.
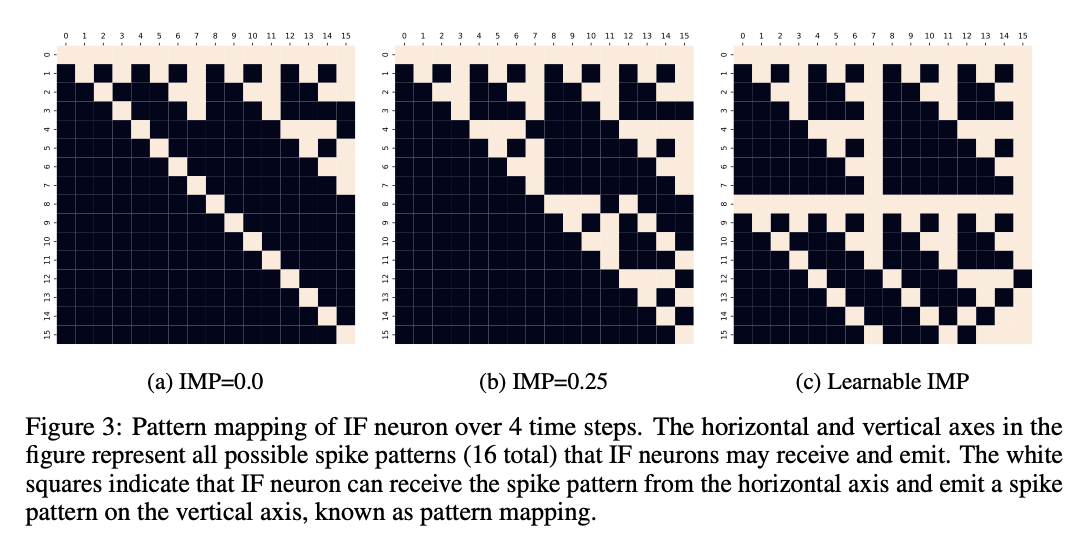
除了对输入编码的影响外,我们的主要关注点是修改 IMP 是否可以增强模型的能力。对于 ANNs,人工神经元可以通过调整权重将任意单一输入变量映射到任意值。类似地,我们希望脉冲神经元也能将输入序列映射为尽可能多的发放模式,从而提升网络的表征能力。如图 3 所示,每种输出模式至少有一个可用的模式映射。然而,图中存在黑色区域,这表明无论如何调整突触权重,某些模式之间的映射仍然无法建立。图 3b 显示,通过将 IMP 从 0 调整为 0.25,可生成额外的模式映射。此外,图 3c 展示,当 IMP 可学习时,其在建立模式映射方面表现出更大的潜力。因此,我们认为可学习的 IMP 可以有效提升脉冲神经元的表达能力。
3.3. Membrane Potential Evolution in Static Tasks
把SNN沿Timestep推理的行为写作:
这里一般不考虑input在时间上的变化(采用的是average encode input?为什么不是analog?),可以简写成
Observation 3: In static tasks, the accuracy of SNNs at the each time step is sensitive to the current MP.

就是说,模型在多个timestep上拥有相同的输入和相同的weight,只有自己的state发生了变化,但是不同timestep上的精度快速增加,证明模型的输出完全由决定。
Observation 4: TET performs well on the neuromorphic tasks but exhibits slow convergence on the static tasks.
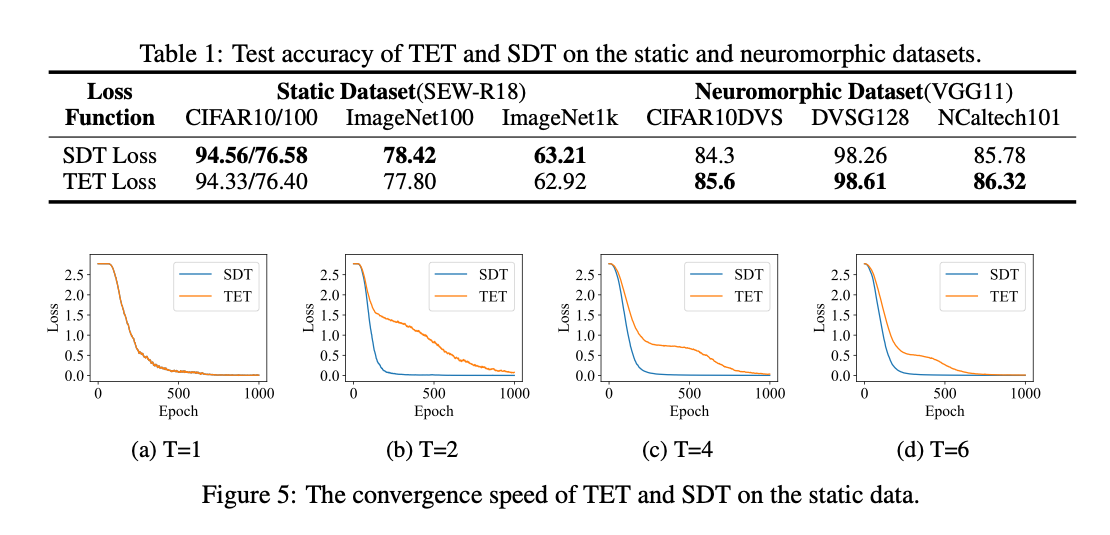
我们比较了静态数据集和类脑数据集上的 SDT 和 TET 损失(如表 1 所示)。尽管 TET 损失在类脑数据集上具有显著优势,但在静态数据集上不如 SDT 损失。这一现象的原因在于静态数据集上的恒定输入强度使得膜电位成为动态系统中唯一随时间步变化的项。而 TET 损失的优化目标是使网络在每个时间步输出正确结果,导致收敛速度较慢。与此同时,如果 SNN 对 不敏感,即所有时间步的输出趋于相同,则后续时间步的计算变得多余且无意义。
4. Methods
4.1. Learnable IMP
基于观察3,修改IMP有助于模型的Accuracy。把timestep = 0 的膜电位变成:
4.2. LTS Method for the Static Tasks
只保留最后一个timestep作为输出,然后按照LTS Loss训练。
4.3. Label Smooth TET Loss for the Neuromophic Tasks
原始的TET方法额外添加一个正则项控制输出层的发放水平:
是目标发放水平。
文章认为这个正则项阻碍了模型的训练,因为当Loss收敛到0的时候,,模型每个timestep输出的内容是常数,无法分类。文章认为使用标签平滑CE代替原始CE,然后移除比较合适:
5. Experiments
5.1. Exucution Speed Benchmarks of IMP
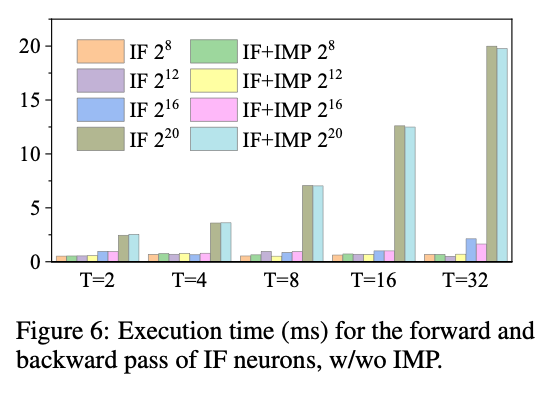
引入IMP对运行速度没什么影响,因为主要还是计算操作本身的耗时。
5.2. Convergence Speed of LTS on the Static Data
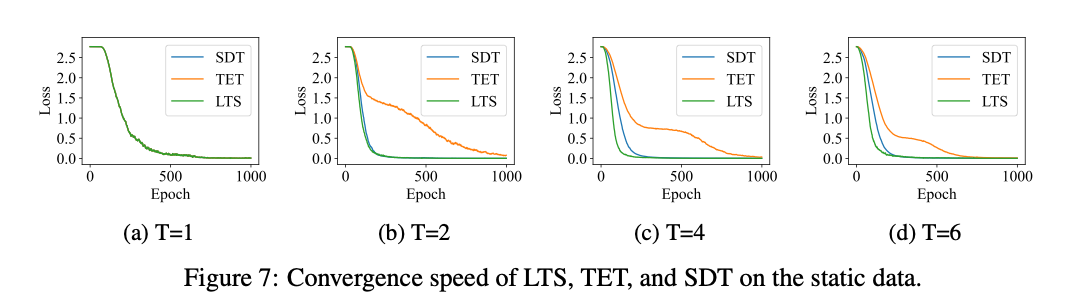
加速了收敛。
5.3. Performances on the Neuromorphic Data Classification

5.4. Performances on the Static Data Classification
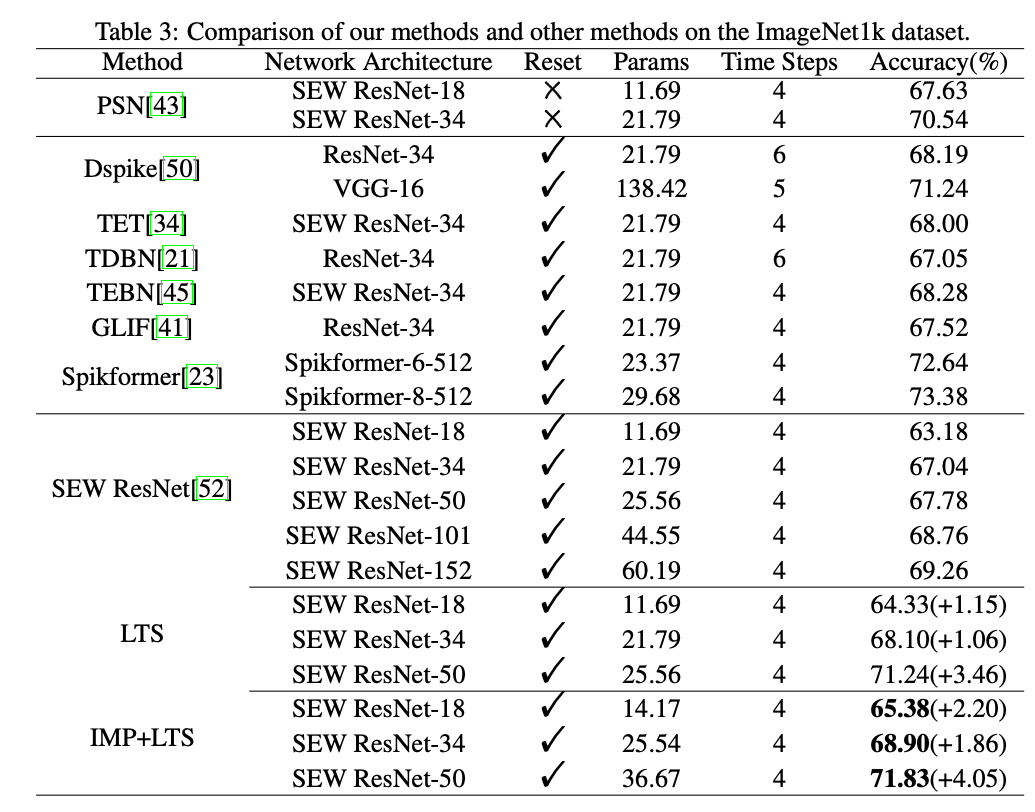
5.5. Further Ablation Studies

6. Conclusion
我们通过重新思考 SNN 的膜电位动态机制,提出了一种可学习的初始膜电位(IMP),以增强脉冲神经元的动态机制。此外,我们针对静态任务提出了 LTS 后处理方法,并针对类脑任务提出了标签平滑的 TET 损失函数。值得一提的是,我们的方法只需要对脉冲神经元的设置和损失函数进行极少的修改,即可有效提升 SNN 在静态任务和类脑任务上的性能,同时几乎不增加额外的计算开销。由于我们提出的方法具有对现有模型结构和训练方法的广泛兼容性,它可以被广泛应用于现有方法中,从而进一步提升网络性能。
也没有很rethink,这种adaptive的初值感觉实际没什么价值,提点提的也不怎么多,测试的数据集也特别小。比较乏善可陈的一篇文章。